I have always had this habit: whenever I see a good article, I save it first.
Technical blogs, Hacker News posts, AI news, high-quality links shared by other people. I put them into Readwise and tell myself I will read them slowly later.
You can probably guess what happens next. I suspect many people are the same.
I save faster than I read.
After a while, the Inbox in Reader gets longer and longer, and the unread count keeps growing. Opening the app slowly starts to feel like:
How much content do I owe today?
Instead of:
What is worth reading today?
Later, I realized the problem might not be the reader.
The problem was that I had also left the decision of what to read to myself.
When I face dozens of articles every day, the thing that really drains energy is not reading. It is filtering.
So I built a small project:
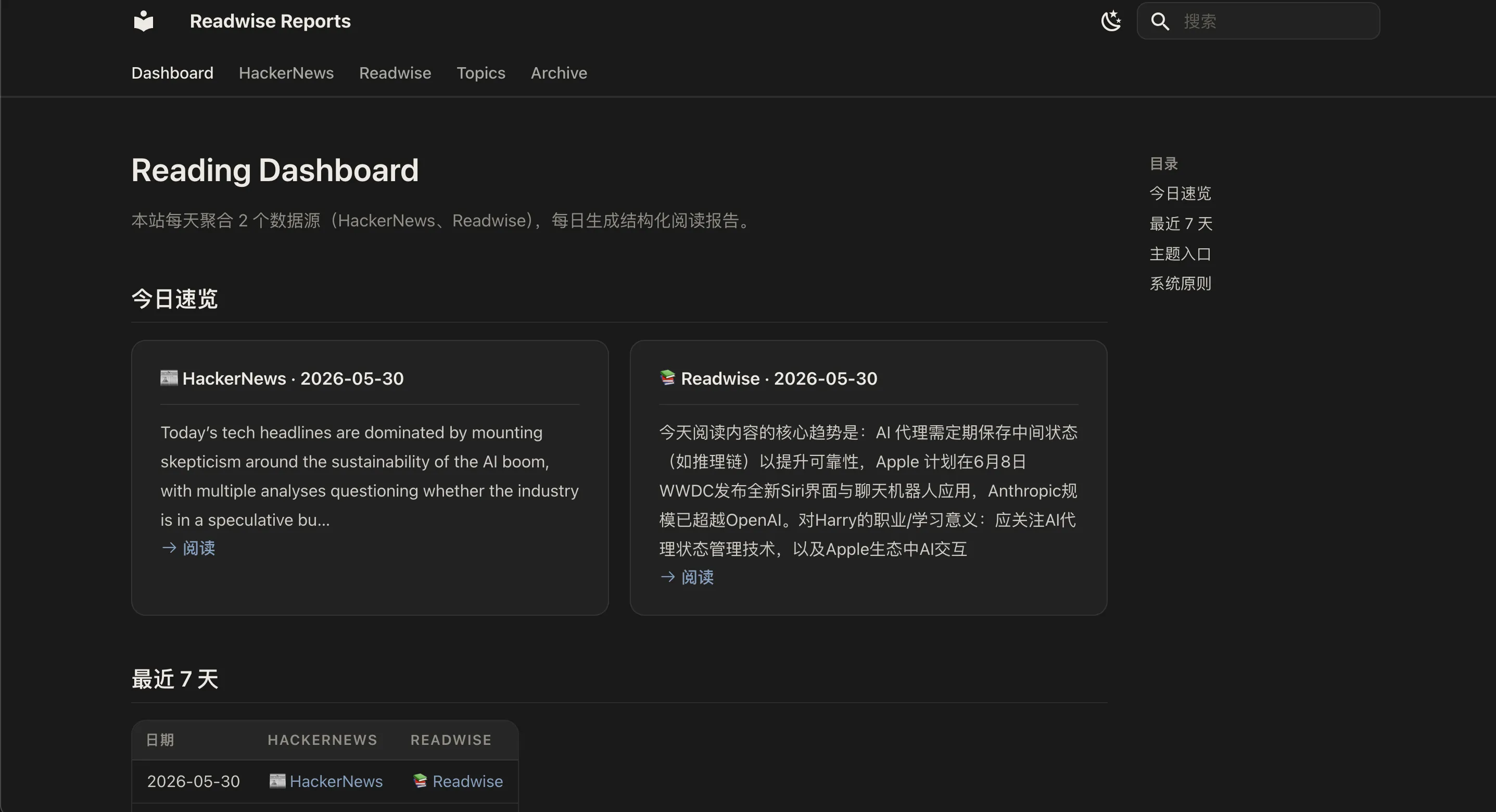
What it does is simple. Every day, it automatically scans the information sources I follow and generates a daily report.
Right now it connects to two sources:
- Readwise
- Hacker News
AI reviews the content first.
- Which pieces are worth reading carefully.
- Which pieces only need a quick skim.
- Which pieces can be skipped.
- It also adds summaries along the way.
Finally, it generates Markdown reports, archives them in a repository, and displays them through a simple website.
Information that used to be scattered across different places becomes one daily report.
When I open the site every day, I am no longer facing hundreds of candidate articles. I am facing a reading list that has already been ranked.
At the beginning, I only wanted to write a script.
Fetch data from Readwise -> send it to AI for summarization -> write Markdown -> done.
But halfway through, I noticed a problem.
Today it is Readwise.
Tomorrow it might be Hacker News.
The day after tomorrow it might be GitHub Trending.
Later it might be some newsletter.
If every new source forced me to modify the main workflow, this thing would quickly turn into spaghetti.
So I gave myself a rule:
One data source, one Skill.
Readwise is a Skill.
Hacker News is a Skill.
If I add more sources later, each one will also be a new Skill.
Each Skill is responsible for its own pipeline:
fetch -> dedup -> AI -> writeIn other words:
fetch
↓
deduplicate
↓
AI processing
↓
generate reportIt does not need to care about anything else.
Then I placed a very small Kernel in the middle. It intentionally knows almost nothing. It does not know Readwise. It does not know Hacker News. It does not know what sources I might add in the future.
It only handles:
- Finding available Skills
- Providing shared capabilities to Skills
- Running them in order
Roughly, it looks like this:
flowchart LR
subgraph SRC[Data Sources]
direction TB
RW0[Readwise]
HN0[Hacker News]
NX0[Next source ...]
end
subgraph PLUG[Skills]
direction TB
RW1[readwise/]
HN1[hackernews/]
NX1[next-source/]
end
subgraph CORE[Kernel]
direction TB
REG[Registry]
--> RUN[Runtime]
--> SVC[AI · Store · Writer · Log]
end
subgraph OUT[Output]
direction TB
MD[Markdown Reports]
--> WEB[Portal Site]
DC[Discord]
end
RW0 --> RW1
HN0 --> HN1
NX0 -.-> NX1
SVC -. SkillContext .-> PLUG
PLUG --> MD
PLUG --> DC
I like this structure a lot.
Because the Kernel never needs to know what is happening outside.
It only provides capabilities.
What to fetch, how to fetch it, and how to process it are all decisions owned by each Skill.
There is also a small detail I personally like.
Inside a Skill, the way to call AI is always:
ctx.ai.complete(...)If an API key is configured, it directly calls OpenAI, Claude, or Gemini.
If the whole pipeline is running inside an Agent, such as Claude Code, it can directly use the host Agent’s model capability.
For the Skill, there is no difference.
The same code does not need to change.
I have always felt that the most important test of an architecture is not how easy it is to add features.
Everyone can add things. The hard part is deletion. If one day I decide a source is no longer useful, I want this to be all I need:
rm -rf skills/some-sourceAnd then it is over.
No registry.
No configuration sync.
No scattered checks like:
if (source === "xxx")The next time the system starts, the Kernel no longer scans that Skill, so it naturally disappears.
It is not in the daily report.
It is not on the website.
It is not in notifications.
The world returns to the state it was in before that source appeared.
Looking back at the project later, I realized that what I built was probably not really a reading tool.
Because the fact that there is always more content is not something I can solve.
I may solve today’s pile, but tomorrow there will be more.
What I really wanted to solve was something else:
In an age of content explosion, outsource the step of deciding what to read.
Let AI read through things first.
Let the system filter things first.
What is left for me is the handful of pieces most worth reading that day.
Not being able to read everything is still normal.
But now, something reads the first pass for me.